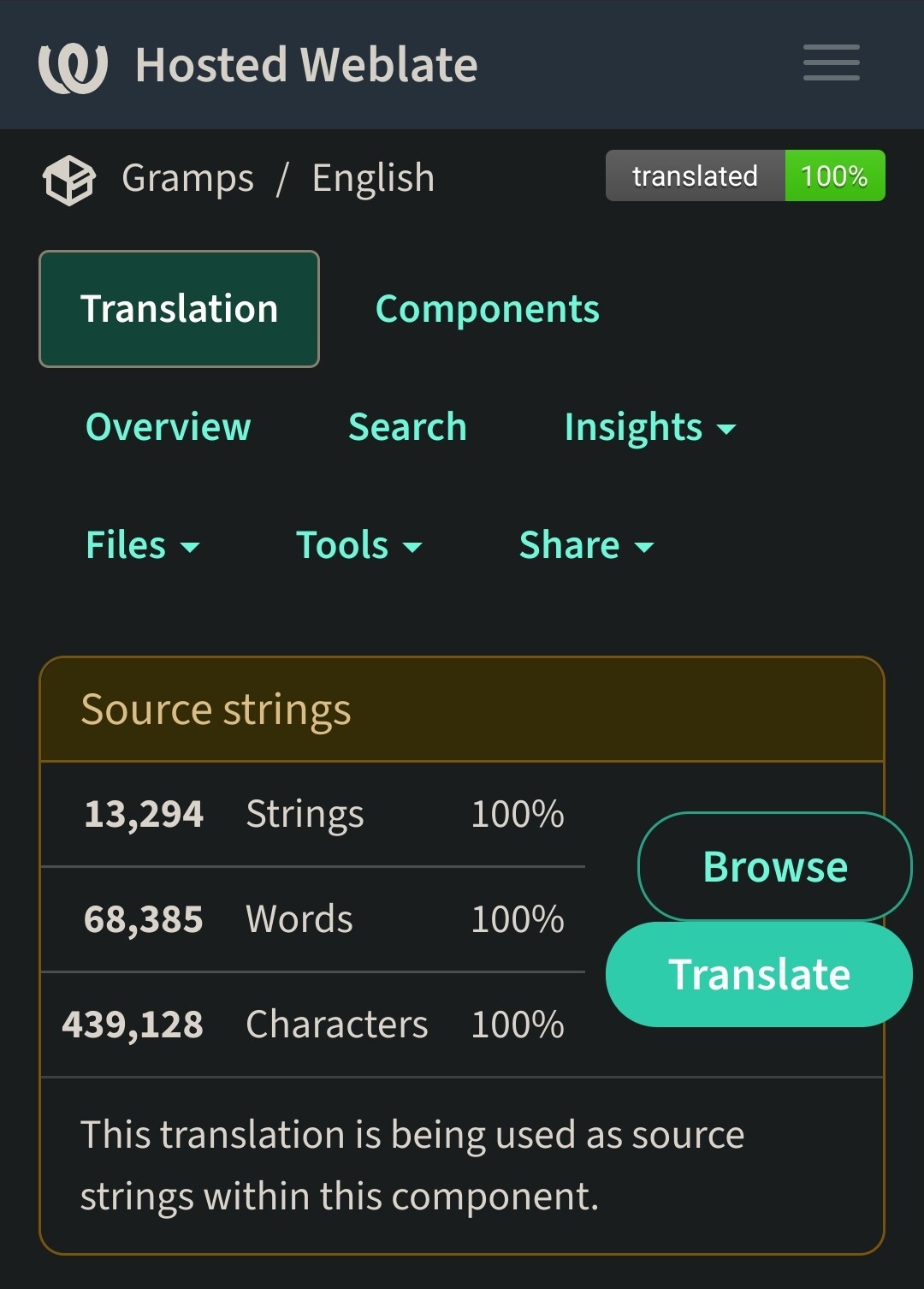
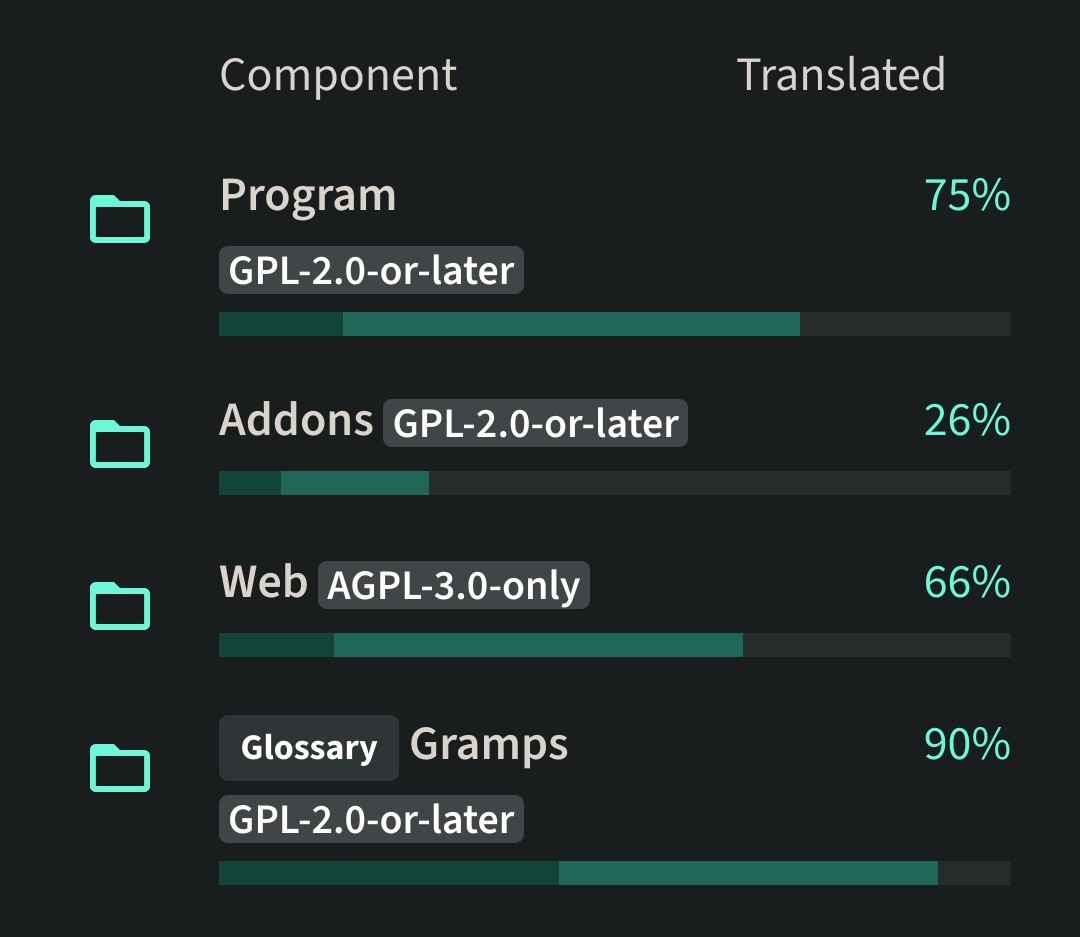
The Weblate glossary for Gramps has grown to over 13 thousand strings. It seems like that should be sufficient to communicate most concepts. Yet the glossary continues to grow. (When I recall checking the count last year, wasn’t it around 8 thousand?)
Should there be a new part of the source validation process that compares translatable strings to the existing strings? Where it finds new entries and recommends a possible equivalent string from the existing glossary?
Another LLM process might be to find phrases that are re-wordings of each other. Where it could recommend consolidations.
In theory this is a good idea as long as the processes that are used are able to understand the semantics of the strings in question.
Within Gramps core code de-duplicating strings makes, since it would promote consistency. In the addons repo it may not be easy since addon authors might want more autonomy to change strings without affecting all other addons.