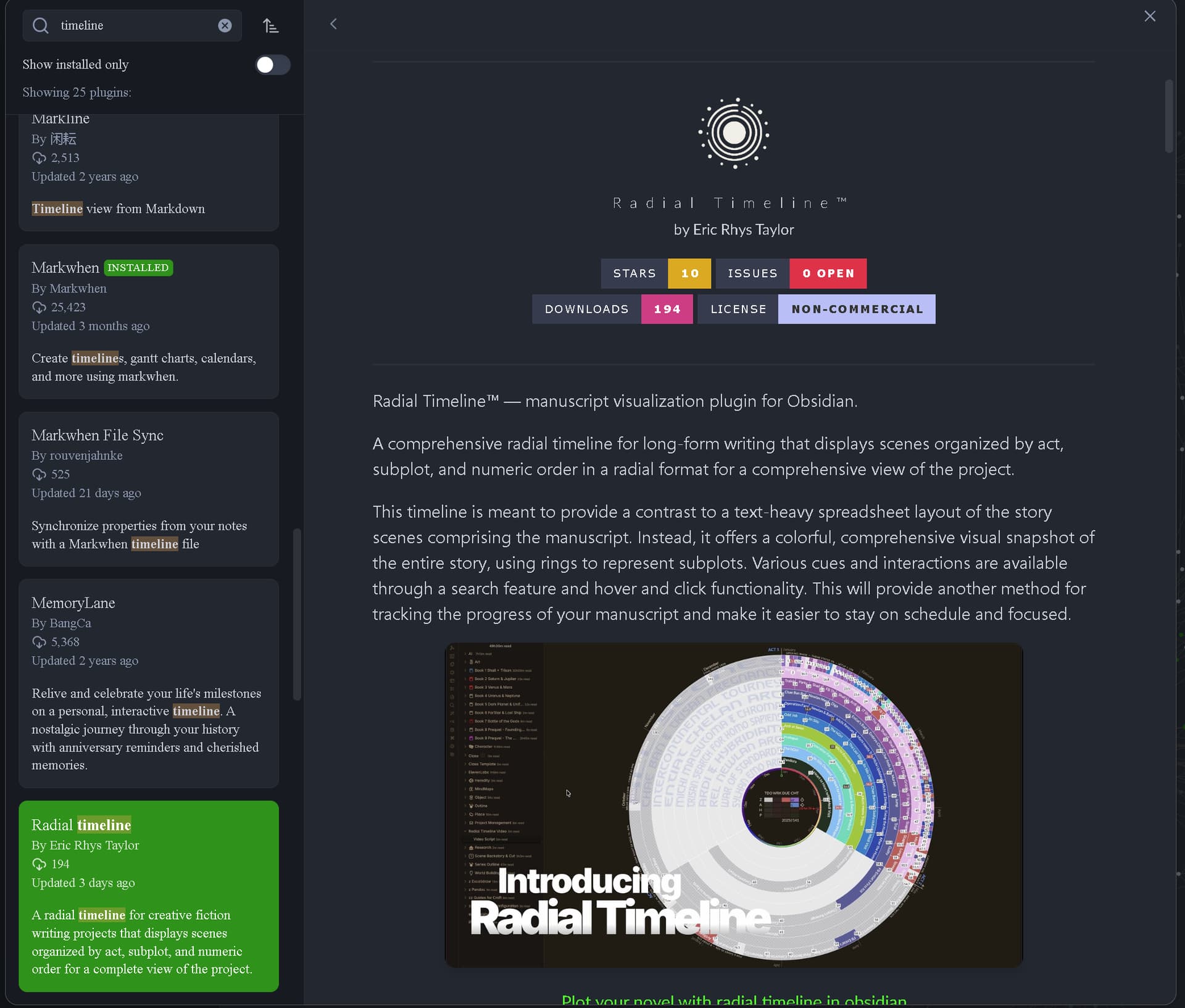
Computeractive Sept 2025: best genealogy tool for Linux?
Another plug (less flattering this time) for gramps in computeractive
Computeractive 10 Sept 2025, Iss 718, p. 20 https://getcomputeractive.co.uk/
Computeractive Sept 2025: best genealogy tool for Linux?
Another plug (less flattering this time) for gramps in computeractive
Computeractive 10 Sept 2025, Iss 718, p. 20 https://getcomputeractive.co.uk/
There is a big problem with Ancestris, and that is that it uses GEDCOM as it’s working database file…
Hello,
I’ve never tried Ancestris, but what’s the downside to using a gedcom file as a database?
Response time or limitations to information permitted by gedcom ?
Bertrand
Both of those are major limitations.
The original GRAMPS 1.x started with XML as the working data format. (A bit more structurally efficient than GEDCOM, but still the same concept of a text-based storage system.) Version 2 moved to a relational database (BSDDB) for performance reasons. (And to SQLite with version 5)
XML was far more extensible than GEDCOM for information that can be represented as structured data. But it was still too inefficient when the relationships grew complex. Inserts, changes and deletes took too long to write. And finding all the related records required moving too much data for every operation.
Thanks for your answer !
Hello,
I tried this program with a 35,000-person Gedcom file from Heredis (not known for being very compliant with the Gedcom standard).
Yes, Ancestris is very good on GEDCOM compatibility. For single-record work or just browsing GEDCOM files, it’s solid. It also has a few useful reports and map views.
But it comes with all the limitations GEDCOM brings — and then some. There’s no error correction, no fail-safe if a write fails, no commit feature. If something goes wrong mid-save, you can lose the whole file. And since GEDCOM is just a flat text format, there’s no indexing or relational structure — which means performance and consistency checks are limited.
Still, it’s one of the better open-source and free genealogy tools out there, and often overlooked. It runs on anything with Java, and the interface is flexible once you get used to it.
I use it to inspect GEDCOM files, run quick reports, or just view data. But I wouldn’t trust it for long-form editing or large-scale work — not without backups… a lot of them… I have lost a few GEDCOM files using it, but still, I don’t have anything really bad to say about it…
hello,
And how do you switch from one software to another, knowing that Gramps does not (yet) allow you to import witnesses ?
I don’t “switch” between, I actually use Obsidian as my main research tool, and looks t Gedcoms with Ancestris if I need to, then I get the data to Markdown into Obsidian or Foam for VSC…
All sources get registered in Zotero and can be used in Obsidian with a plugin…
From Markdown I start my research and when I find facts that are confirmed, I add it to Gramps and link the Markdown Notes to the Gramps Object.
I also use Aeon Timeline and some Network Graph type software like Gephi, Cytoscape and Tulip.
This is the reason you will see me advocate for Open-Source Open Data import/export formats other than GEDCOM.
Hello
My workflow is much simpler — I only use my genealogy software (Heredis).
I didn’t know any of the tools you mentioned (except for Ancestris and Gramps), so I asked ChatGPT to explain your workflow to me.
It sounds really interesting and quite powerful!
Do you happen to know of a tutorial or a video that shows how it all works together?
Thanks a lot!
There are no videos or tutorials for my workflow.
It’s something I’ve worked out myself over countless hours of testing, trial and error, and tool comparisons.
Hello
I totally understand — your workflow clearly comes from a lot of personal experience and experimentation, so it’s not something that can just be copied by others.
Still, thank you so much for sharing it! I really appreciate discovering this way of working — it sounds full of great possibilities.
Here’s a brief example of how I work:
I begin by registering each source in Zotero — regardless of type — entering all relevant metadata and establishing the appropriate folder structure both in Zotero and in my Obsidian Vault. This ensures consistency and traceability from the very start.
For instance, historical newspapers — such as weekly listings of positional data for over 2,000 Norwegian mercantile ships between 1920 and 1940. I know several of my relatives sailed on multiple of these vessels.
I convert the listings into a CSV file and import it into Obsidian as MD-tables, enriched with wiki-links for each ship, captain, date, departure and arrival port, and other relevant metadata.
Each newspaper source is also linked back into Obsidian using citation plugins, ensuring source integrity and bidirectional traceability.
If I find a ship’s manifest — say, from FamilySearch or digitized US archives — I extract the full crew list into another CSV and Markdown table, again with wiki-links for each sailor. These manifests often include ship names, dates, and other contextual data that help track individual movements. This is crucial, because sailors frequently “jumped ship” — so knowing when someone signed on with a new vessel or went ashore in a foreign port is key to reconstructing their trajectory.
Sometimes I come across a letter or postcard from one of these sailors, mentioning that they were in a specific port at a specific time. I register that item in Zotero as a source, create a note in Obsidian, link it via the Zotero plugin, and add wiki-links for all relevant data — such as place, time, and ship name if mentioned.
As these data points accumulate, I begin to see network graphs emerge — showing connections not only between events and locations, but also between individuals. Many of these people aren’t direct relatives, but they often sailed together, went ashore together, and signed on with new ships together. In several cases, I’ve located missing family members by tracing their shipmates instead.
I also include census data for entire households and addresses. More than once, I’ve discovered that a neighbor was actually a not-so-distant relative — cousins or extended family living in the same building, sometimes even in the same household, but listed as tenants or domestic staff. Norwegian census records often include information about previous residences, which adds another layer of traceability.
All of this goes into Zotero as sources and is linked back to my Markdown notes in the Vault.
I maintain Markdown notes not only for people and sources, but also for events, places, objects, and more — all organized in a folder hierarchy (see attached example). This structure is mirrored in Zotero and in any other software I use that supports it.
Across Gramps and all other programs I use, I link the relevant Markdown notes to each research object or subject wherever possible — including Aeon Timeline, Cytoscape, Gephi, and others. I only do this for long-term research projects; for quick checks or exploratory work, I usually just enter the core data for fast overview.
I don’t enter events or other data into Gramps until I’ve reached a certain level of confidence and source validation. If I encounter objects that consistently contradict earlier findings or prove irrelevant, I still include them in Gramps — so that anyone continuing the work later won’t repeat the same loops I’ve already gone through.
This is also why I’ve moved most of my research into Markdown and Foam/Obsidian — it’s much easier to visualize what’s confirmed, refuted, or still pending. A simple tag or folder structure can show the status at a glance. I mirror this in Zotero using both Collections and Tags.
Obsidian also has powerful plugins that allow me to publish notes and graphs online as pure HTML and JS. There are longform writing plugins, diagram and graph plugins, and several timeline plugins for basic chronological views. But for advanced timeline research, I use Aeon — because when dealing with thousands of events and relationships, a visual timeline is far easier to read than a table.
All of these notes are linked to the respective Gramps objects — including sources, places, events, and more.
I add a little part of my Obsidian Vault as a Print Screen, as well as a print screen of a fraction of a new “template structure” for Zotero that I am trying to create, just to give some idea on how it looks.
—
***PS. this is the short version.
Note: This text was translated from Norwegian and formatted for English flow by Copilot.***
And this is a view of the Network Graph for one of my relatives (one of the sailors)… focused on Newspapers (green) and other ships lists (blue), ports (red) and humans (light blue and pink)
Hello StoltHD,
A big hello from France to Norway
Thank you very much for taking the time to provide these detailed explanations and screenshots, which clearly demonstrate how organized and well-charted your research is.
For my part, my research is traditionally done by browsing French religious archives (before the Revolution), civil status archives (after the Revolution), and also notarial archives.
And there are a lot of them!
However, managing questions, assumptions outside of the genealogy software seems like an excellent idea to me, and software like Obsidian (which I’ve just started learning) is a perfectly suited tool.
Thank you again for introducing me to this methodology.
Have a great day
Bertrand
Just remember not to install to many of the plugins, it’s easy to overdo that in Obsidian…
Read through the descriptions and don’t install more than you need…
There is a lot of good information about them in the forum and on youtube, and try to see a little passed what they were design for to find those who fits your workflow the best.
Hi,
For now, I’m mainly learning with YouTube and ChatGpt.
I only have Calendar and Templater installed.
But there’s definitely an impressive selection of plugins (I don’t think I’ll ever look at them all)
You should take a look at the
And maybe the Graphviz plugin, because I think it can visualize a graphical report from Gramps with a little tweaking, PS. I have never tried to do that.
Edit:
I just found this YouTube video on using Zotero and Obsidian for historical (archival) research. Definitely worth the time.… https://www.youtube.com/watch?v=i-CJ-SmU7rA
Good evening,
Thanks for these plugins, which I’ll look into.
For now, chatGpt tells me that in its latest version, Zotero no longer has a local server and can therefore no longer be queried directly by Obsidian.
This loses much of its appeal. ![]()
Bertrand
Zotero and Obsidian still work perfectly together via plugins.
The interoperability no longer relies on Zotero’s internal HTTP server, but uses updated APIs and bridges instead.
Thank you !
ChatGPT question
slight_smile: Hi! ![]()
I’m talking with ChatGPT about integrating Zotero and Obsidian.
You mentioned that Zotero and Obsidian still work perfectly together via plugins, using updated APIs and bridges instead of the old internal HTTP server.
ChatGPT and I would really like to know which plugin(s) you’re using for this integration.
Are you using Zotero Bridge, Zotero Integration, Zotero Sync Client, or something else?
Thanks a lot for your help!
Bertrand