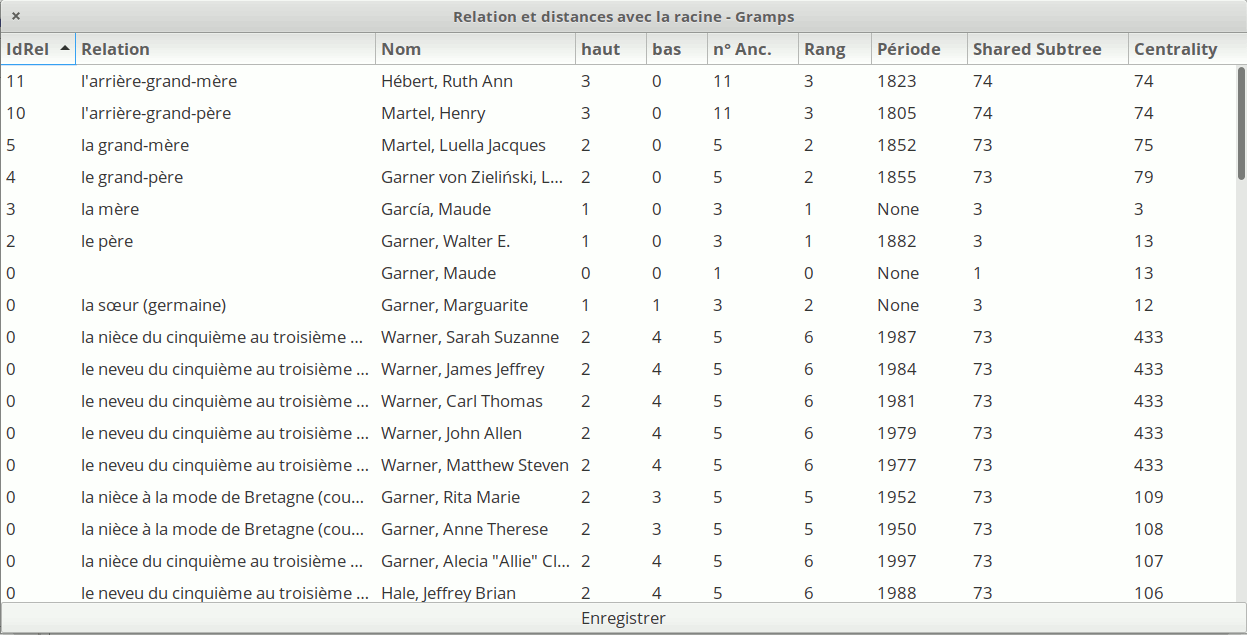
Hello !
I am starting and looking at a little bit refactoring and performance issues on an old 3rd party addon. It was generated some years ago and tested with old hardwares and few resources. So, the idea was to generate (Yet) another alternated interface to Relationships Calculator module and to provide an output (via an hack of standard way for OpenDocument Spreadsheet exporter).

Performances sounded good by using
example.gramps data (less than 5 secondes for calculations and display) with default values (generations depth).
As filter rules performances have been improved on Gramps 6.x, (and before making migration from 5.2 to 6.0), I started to look at ways for improving this addon tool. As it re-uses many times the Relationships module and as this could be expensive (memory, calculation), maybe the first step might be a quick refactoring. Also, the more number of columns will increase, the more it needs time for calculations and display. So, maybe something around this too.
The first exploration (on my side) is to try to look at threading and multiprocessing modules. It makes sense for more modern configurations and more and more large dataset. It is the first time that I use/call it. The basic test was to replace some possible expensive sections and put it them to their threads.
Well, the total time process increases from 5 secondes to 12 secondes with a simple database and default values (~2000 individuals)! I did not test with large databases. So, is it normal or I generated more mistakes with threads? Here a link to these first changes (tests, experimentations):
Something looks wrong to my thread usage and implementation.
- filter.add_rule(related)
- self.progress.set_pass(_('Please wait, filtering...'))
- filtered_list = filter.apply(self.dbstate.db, plist)
+ t_filter = Thread(target=self.t_filter_rules(related, plist))
+ t_filter.start()
+ t_filter.join()
+def t_filter_rules(self, related, plist):
+ """
+ """
+ self.filter.add_rule(related)
+ self.progress.set_pass(_('Please wait, filtering...'))
+ self.filtered_list = self.filter.apply(self.dbstate.db, plist)
Should I rather try to make a pool for threading? Or should rather improve the monitoring[1]? It looks like iteration and filtering might be different on Gramps 6.0, but I need to first improve it on 5.2.x, for understanding ways and modifications.
[1] $ gramps -d “relation_tab”
Best regards,
Jérôme