Gramps 5.2.3
Gramps Web API 2.5.2
Gramps Web Frontend 24.10.0
Gramps QL 0.3.0
Sifts 1.0.0
locale: en
multi-tree: false
task queue: true
OCR: true
chat: true
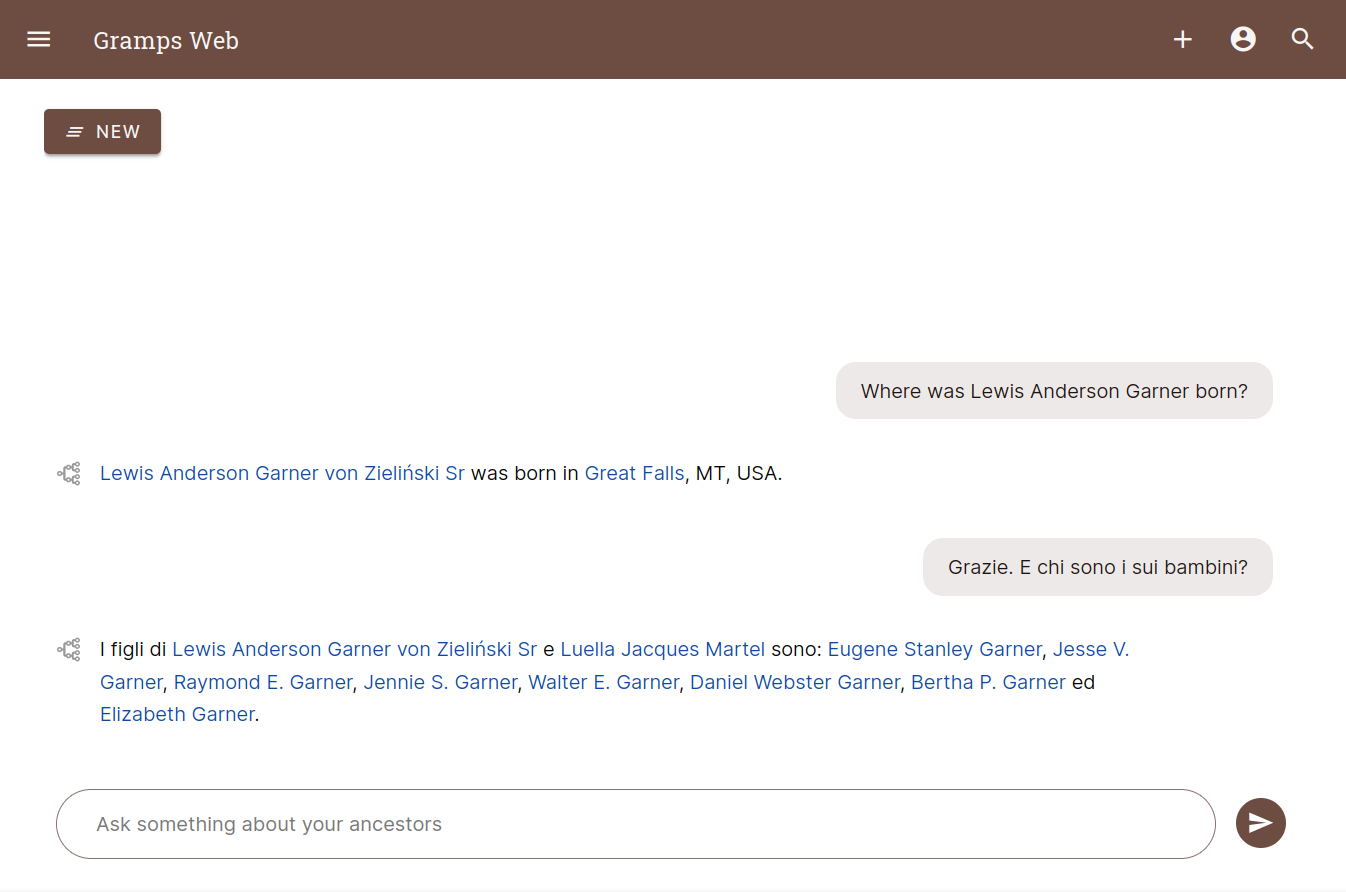
Chat is running with Ollama [Ollama description] using phi3:mini model. However, the sample query, “Where was Lewis Andersen Garner born?” and variations all resulted in “Invalid message format” response until I rebuilt the semantic search index.
After reindexing, I started getting responses, but based on the responses, it feels like RAG isn’t being used because the chatbot is responding with things like this…see snapshot. Similar results for other people in the Gramps sample tree; it gives info for similarly named people from the internet.
Good suggestion, tried it, but the model is still hallucinating (see attached).
First question for you about models with Ollama setup: Is model download a pre-requisite step?
I specified GRAMPSWEB_LLM_MODEL: "tinyllama" but the model was not downloaded automatically (same thing with phi3:mini previously); chatting at this point results in “Chat API error encountered”. To get around this I exec’d into the ollama server and downloaded the model manually issuing the following and then chat worked: ollama pull tinyllama.
As mentioned, even with tinyllama the model is still hallucinating. I updated the semantic search index, which initially took 21 minutes to build when I had phi3:mini configured, but the update took only a few seconds (expected?).
Strangely after restarting the docker compose session, the update index seems to have triggered a full rebuild so I will update this thread when it’s compete.
Happy to try out any other suggestions/debugging steps. Thanks.
Unclear on location of SQLite database, but I’m using the sample docker-compose config from grampsweb-docs.
Anyway, even after full semantic search index rebuild and restart of docker compose, chat continues to hallucinate. I will take a break for now and try something different.
@DavidMStraub In at attempt to increase the logs, I modified the docker compose file to this:
command: celery -A gramps_webapi.celery worker --loglevel=DEBUG --concurrency=2
to see DEBUG level messages in the chat section of the code however, none of those are logged, although I do see a few other DEBUG level messages. How can I get at the messages from the chat section of the code? Thanks.
Good news - I switched from Ollama to a provider and I’m getting results that match the chat snapshot on the Features page of GrampsWeb. This gives me confidence that generally speaking my configuration is set up for Chat, including the env vars for LLM, OpenAI key, and sentence transformer.
Appreciate any additional advice on debugging the Ollama container setup from anyone who may have worked through it. Out of curiosity, how many people have the Ollama setup working?
Thanks.
Irritating that there isn’t a simple introduction of Ollama on their GitHub README.md or Domain.
From arsturn.com blog: “A complete tutorial on using ollama” Ollama is an innovative open-source framework that allows users to run various large language models locally on their computers. It’s designed to simplify the installation, management, & use of these models without the need for complicated cloud setups or massive server resources. Whether you’re looking to build applications, perform document analysis, or simply tinker with AI, Ollama is your go-to solution.
Hi @DavidMStraub I agree with you about the system prompt. First, I enabled Ollama debug logging with OLLAMA_DEBUG=“1”. Based on logs I suspected that the models I was using weren’t up to spec because tinyllama had context length 2048 which perhaps was not big enough. phi3:mini had the same context window and didn’t seem to support the <|system|> parameter. So I downloaded phi3.5 which has context length 131072 and supports the system prompt.
Unfortunately the results are still no good, and I continue to see the messages (below) in the log, which I believe implies that the input context is being ignored. (1) Is that interpretation correct, and (2) why is the context being rejected?
Could you share a link to a specific model which works for you?
2024-12-11 18:49:54 time=2024-12-11T23:49:54.946Z level=DEBUG source=prompt.go:77 msg="truncating input messages which exceed context length" truncated=2
2024-12-11 18:49:54 time=2024-12-11T23:49:54.946Z level=DEBUG source=routes.go:1464 msg="chat request" images=0 prompt="<|user|>\nWhen was Lewis Anderson Garner born?<|end|>\n<|assistant|>\n"
...
you can reduce the LLM_MAX_CONTEXT_LENGTH configuration parameter (e.g. env var GRAMPSWEB_LLM_MAX_CONTEXT_LENGTH), which defaults to 50000 (careful: those are characters, not tokens) to avoid this error.
Unfortunately I don’t have much experience with other Ollama models so far as I don’t have potent enough hardware and mostly used OpenAI.
Hi @DavidMStraub
Thanks for the continued support. Did a lot of experimenting, researching and more experimenting with the context length issue and ultimately decided to shelve trying to make Ollama work on my PC in the context of GrampsWeb. Here’s why.
Decreasing LLM_MAX_CONTEXT_LENGTH to various lower values didn’t make a difference. I went down to 8192, but the context truncation errors persisted. Then I tried to increase the context of the phi3.5 model, but the system responded by telling me I don’t have enough memory to do that. So finally I decided I have to stick with a service that provides OpenAI API for now. Perhaps in not too distant future I will have a system with more RAM and a powerful discrete GPU to make this work for Gramps.
However, I will continue learning more about how to use Ollama with context and prompts and see if I discover anything else.



{kind=link}