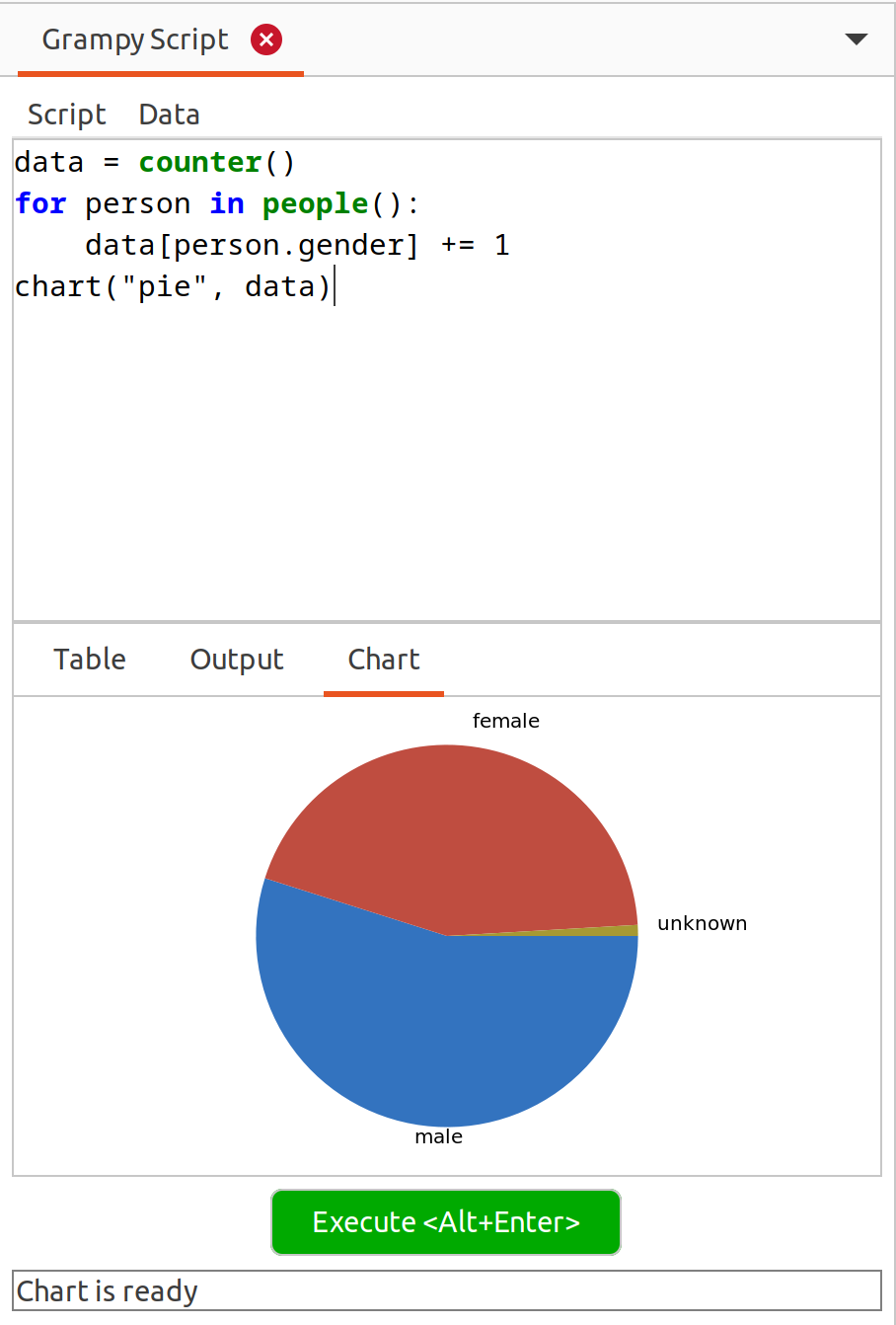
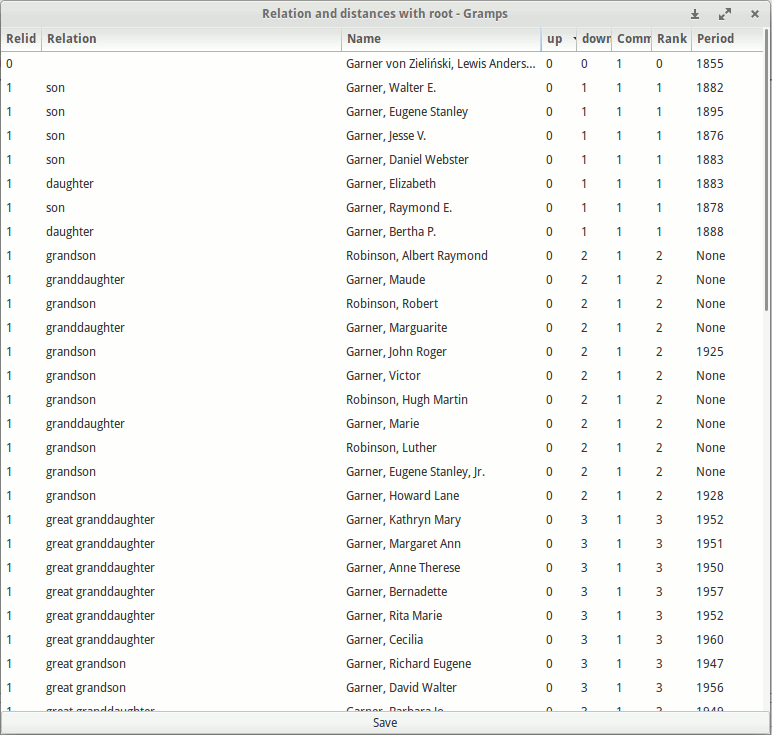
I really like the idea of the SuperTool script-like things. But there were somethings that might be done differently now with Gramps 6.0. And I have some ideas. So I thought I’d take a stab at reimagining portable scripts for doing things in Gramps. And thus Gram.py Script gramplet was born.
First, it was just added to source-addons so isn’t published yet. (I’ll also note that this is PR #666, so beware).
Can Gram.py list keys and values (attributes) on Citation objects, then group by these keys? Same idea around associations on Individuals, maybe like a relations graph!
for person in people():
for citation in person.citations:
for attribute in citation.attributes:
row(person,
citation,
attribute.type.string,
attribute.value
)
Yes, all of the active objects are defined (if a view is loaded), like active_person, active_note, etc.
Wow… interesting. Are seriously thinking about doing that via a script? I would think the CSV Import through the Text Import would be easier. But let me know if you are serious, and the use-case.
Oh, it is oriented individuals, like the gedcom. It was rather a test for the challenge… I know that Note are not really (or always!) primary object and that the citation objects are (I do not know the expression in English) like an “Exception”. I rather thought as Citation as the top level. Something like a starting point (Citation → Sources → Repositories → Individuals → Events → Relations , then an infinite loop…)
Anyway, the same idea could be around attributes, adresses or associations, … into all people.
for person in people():
for attribute in person.attributes:
row(person,
?,
attribute.type.string,
attribute.value
)
I know, to retrieve data from secondary objects might be a challenge…
You can get backreferences, just by setting the parent object?
Does ‘repositories’ exist as a new built-in (hardcoded?) list of objects?
This might deprecate (deprecating?) some very old addons, like for this output:
There are some short-cut/aliases for some items (like person.name is just short-cut for person.primary_name, and person.names is short for [person.primary_name] + person.alternate_names]) and some alias for looking up an object, like person.mother (uses the SimpleAccess methods), but all of the real object attributes are also there.
All items are lazily loaded, and most use fast data lookups (without making objects if possible).
Most above columns are extra stuff (can skip them), but the idea behind this addon was to group (order) according to distance to the active (or root) person. A simple representation of the relationship calculator but with columns and grouping feature.
I would like an easy way to “clone” things. For example, I have a new source that is very similar to an existing source (say, a census). Ideally I could right-click on the existing source and select “Clone”. But running a script that clones the active source would be fine. The script could prepend "[Clone of] " or something like that in the title. Ideally the script would also create a repository reference for the new script, matching the old one (just for the Repository, not for things like Call Number).
A similar example is cloning an existing citation to create a new citation for the same source, leaving the Volume/Page and Date blank.
Though I would still need to edit the newly created source or citation, it seems like it would save me a lot of clicks in selecting the repository or source.
Could such a script also display a dialog with check boxes etc., so that I could refine what it does each time?