As we begin to explore new Gramps Enhancement Proposals (GEPS), it is important to measure the impact that various changes might have on performance.
To that end, I’ve started a new project that will live outside of gramps core that will measure the timing of various database functions. (It should live outside of gramps because the versions of the testing will be independent of the version of gramps).
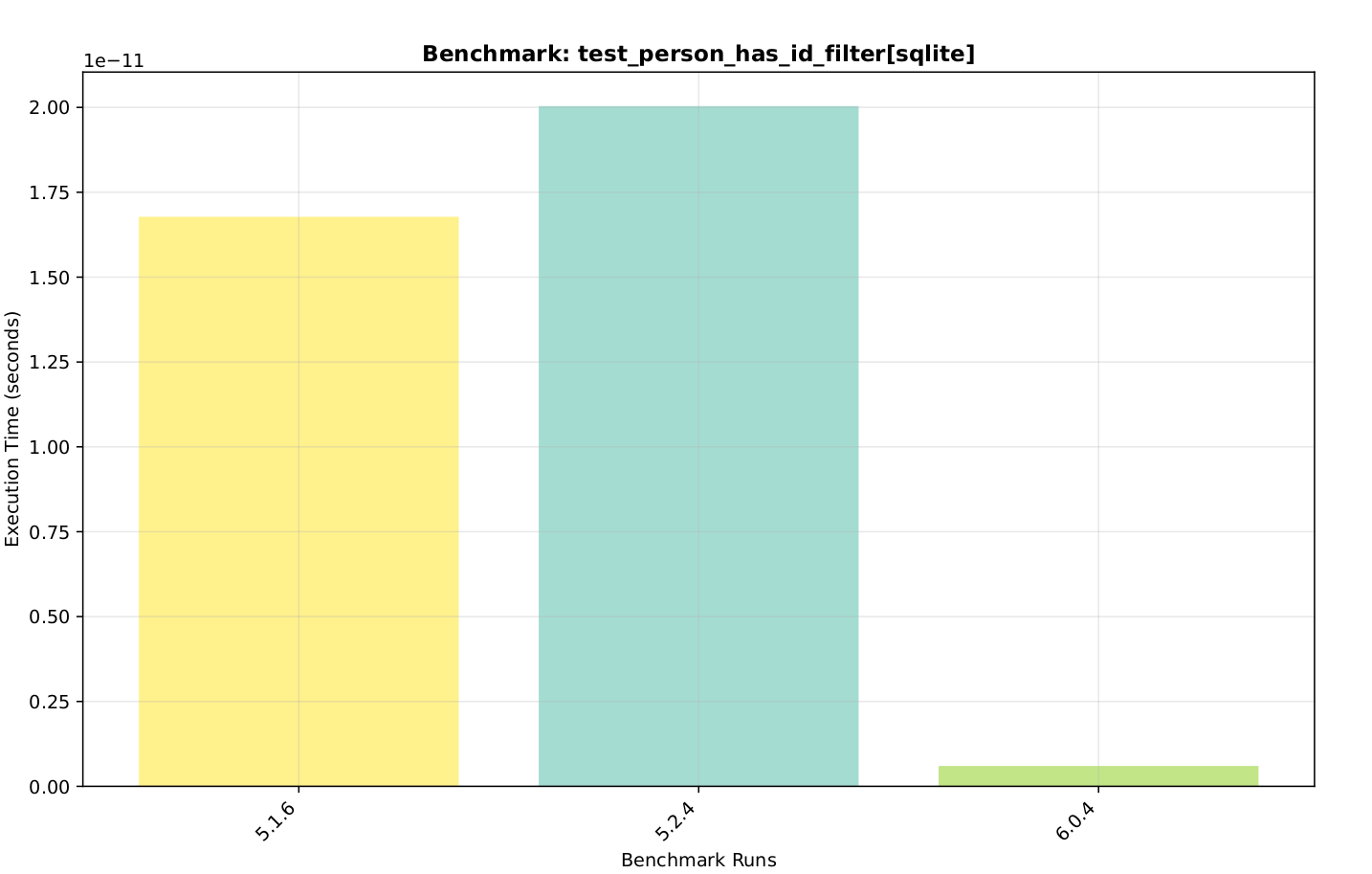
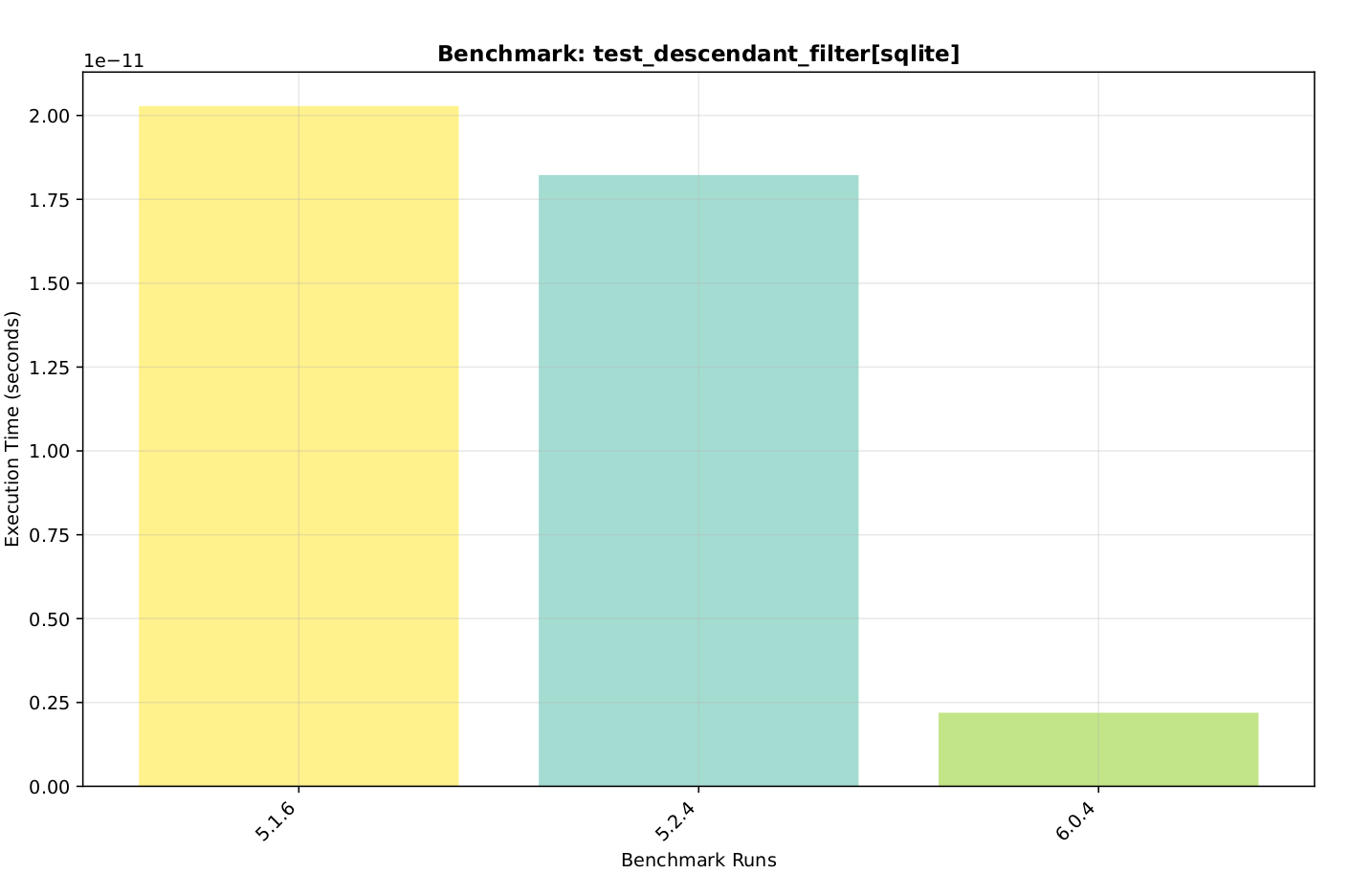
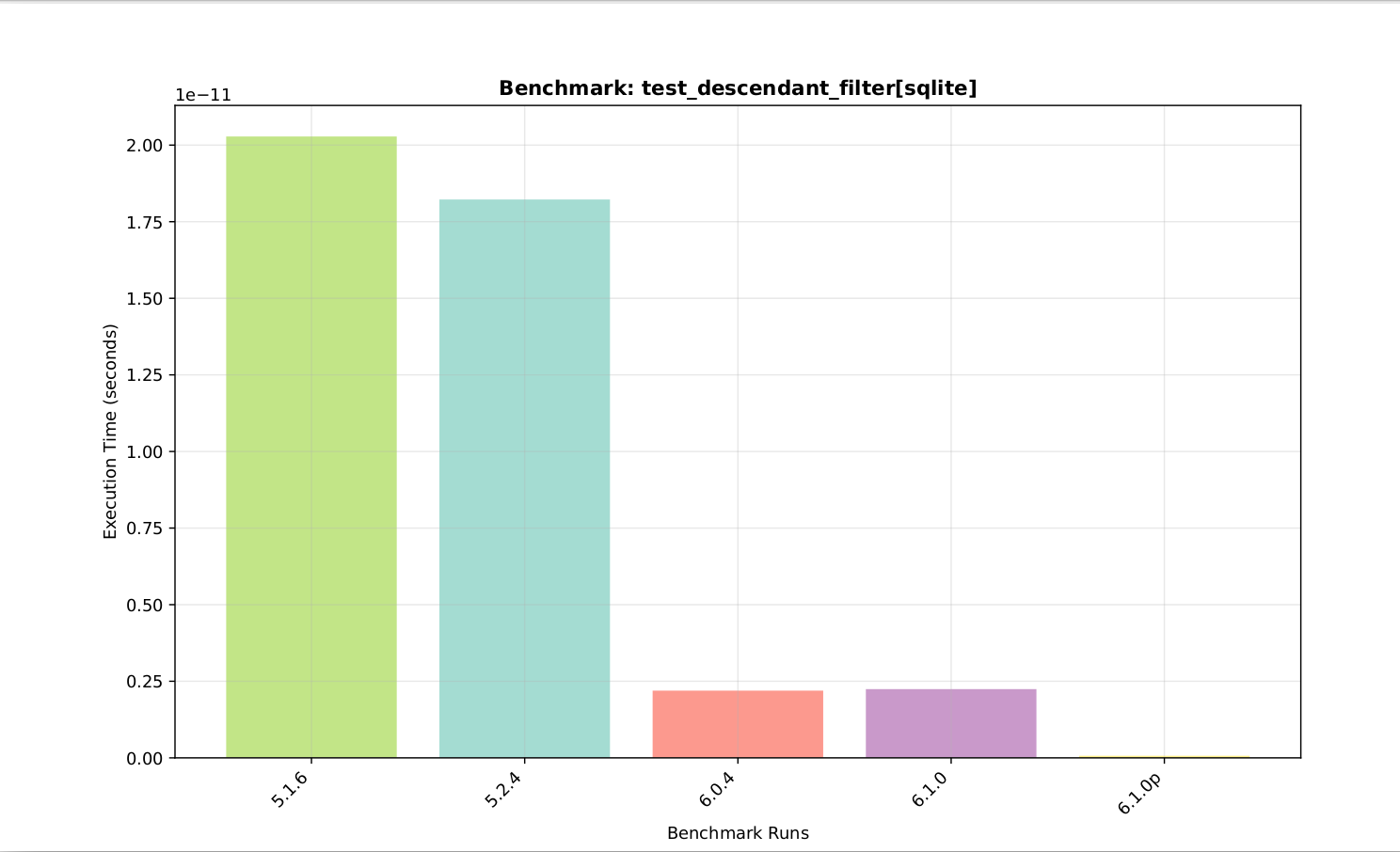
I haven’t seen overall comparisons looking at particular functions over various versions of Gramps. Here is one showing the 6.0 filter optimizer compared to 5.1 and 5.2.
I’ll make a repo soon and keep up to date stats on recent versions, and allow developers/others to run the tests themselves. Can also provide data as to what needs to be improved.
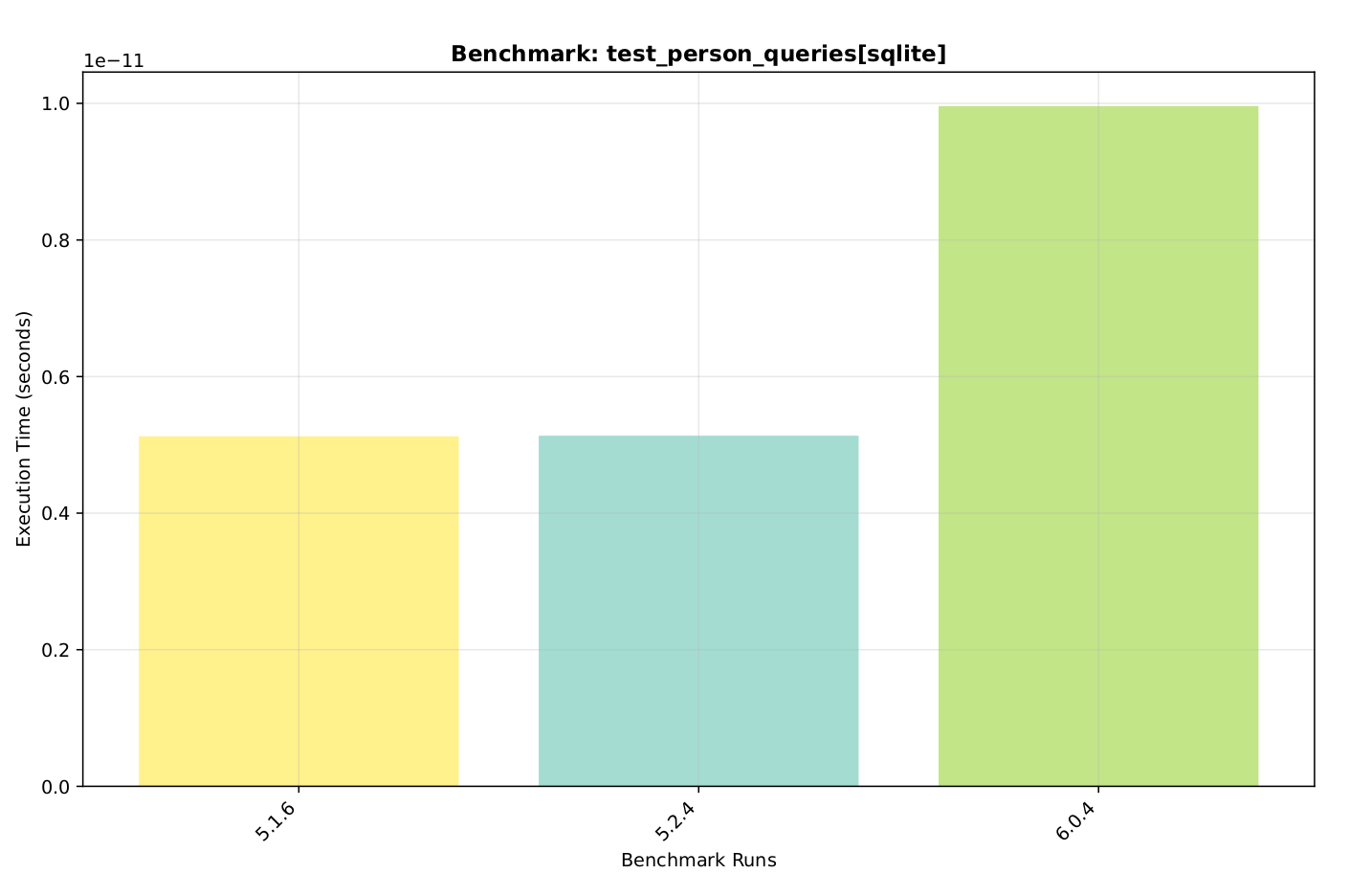
In testing some of the suggestions made by AI, I started with a database config for setting SQLite pragma values (called “config” in chart below). One interesting big difference is in the db.get_person_by_handle() method:
As you can see, it reduced the time by 50%, back down to version 5 times. However, it doesn’t seem to reduce the time of other lookups. Why? I don’t know yet. They all seem to have indices. Perhaps it is in the ordering of the tests…
Yes, right now I am using the example.gramps file:
cd gramps-bench/benchmarks
gramps-bench ~/gramps/gramps/example/gramps/example.gramps --version TESTNAME
But we do need to find a larger one and decide on that going forward.
I was thinking about writing code to generate one, that way we could always add the newest objects, and object attributes. Or if there is a modern gramps-specific one that has close to 100k people, that could work.
One thing that stumbled upon is that if we use PRAGMA journal_mode = WAL; in the SQLite layer then we can use parallel processing in places like finding ancestors and descendants.
My AI coding environment says:
WAL mode allows multiple concurrent readers to access the database simultaneously. While SQLite doesn’t support concurrent writes, it does support:
Multiple readers at the same time
One writer at a time (with readers still allowed)
This could have a very large impact on performance.
Indeed, it can have a large impact. Here is the example gramps family tree 2,157 people. Finding descendants of random people using a parallel search (using 4 CPUs) is about 40 times faster than 5.1.
From the documentation it looks like it ensures consistent data at the transaction level
For example, if the timeline is
Thread 1: read a Person record
Thread 2: delete the Person and events referenced by the Person
Thread 1: read the events referenced by the Person
then we need to ensure that the reads in thread 1 are a single transaction to ensure consistent data. Am I right in thinking we only use transactions for writes today?